本文を表示しよう
本文の構造
前回まで、ヘッダーの一覧の表示ができました。今回からは本文の表示に挑戦です。
その前に、これから行うコーディングを文章で整理してみます。
- 一つのメールの全部を表示します。
初めの空白行までがヘッダーです。 -
ヘッダーの中に『boundary』が無い場合、ヘッダーと本文だけで構成されています。
本文はヘッダー中の「Content-Transfer-Encoding」と「charset」でエンコードされているので、デコードしてあげれば終了。
- ヘッダーの中に『boundary』の指定がある場合、マルチパート(複数の領域)で構成されています。
その場合、領域の区切りとして『boundary』で指定してある文字列の検索の必要があります。
-
『boundary』で指定してある文字列から、初めの空白行までが領域内の情報部分。
「Content-Transfer-Encoding」や「charset」、添付ファイルであれば「filename」等もある。
これらの指定の後の初めの空白行から、次に『boundary』で指定してある文字列が出現するまでがデータ。
- これの処理を、.(ドット)のみの行が現れるまで繰り返し行う。
以上のことから、肝となるのは
- boundaryで指定された文字列の検知
- ヘッダー、boundary後の最初の空白行のみの行の検知
- デコード
<<メール全文の例>>
メモ:
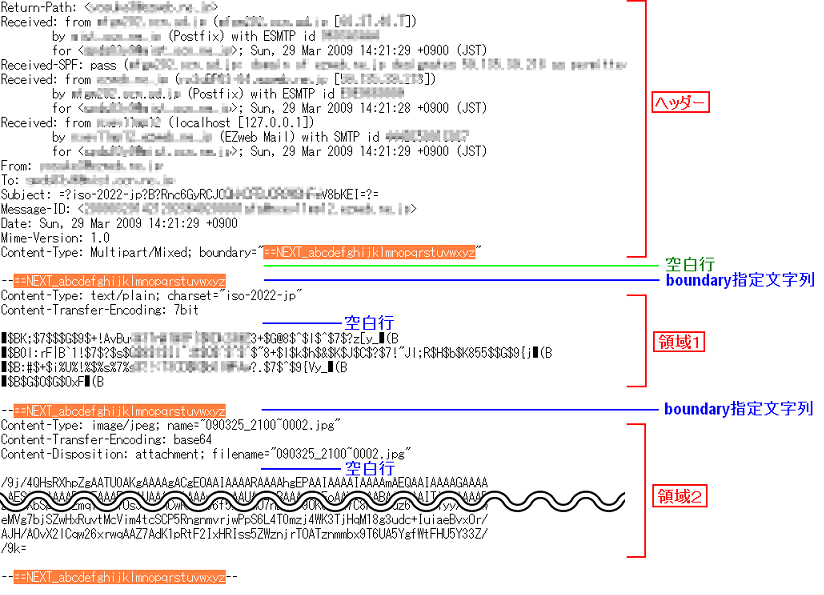
上図サンプルは、添付ファイル付きのメールです。
ヘッダー以外の領域は2つ。これはboundaryの指定箇所の下図で判断します。
各領域の開始から始めの空白行までに、エンコード設定やファイル名などの情報が含まれます。
空白行移行から次のboundary指定文字直前までが実際のデータです。
上図サンプルは、添付ファイル付きのメールです。
ヘッダー以外の領域は2つ。これはboundaryの指定箇所の下図で判断します。
各領域の開始から始めの空白行までに、エンコード設定やファイル名などの情報が含まれます。
空白行移行から次のboundary指定文字直前までが実際のデータです。